Thinking About Innovation
/Drawing a Blank
It’s a brisk autumn morning. You just woke up and you lay in bed waiting for your brain to load the essential bits of information required to start your day. Suddenly, you remember. You just finished a big project and nothing new will be lined up until sometime tomorrow. Today is a free day and you get to work on whatever you want. You get out of bed and start getting ready with a growing sense of anticipation. The sun is shining, there’s an invigorating chill in the air, and a flood of ideas begins to fill your mind. Anything is possible.
You’re one of the first people to show up in the office this morning. You sit at your desk staring at the blinking cursor of your text editor. What to do...so many options. “I could learn a new front end framework. Or I could write that one Rails app I’ve been thinking about in my spare time. Maybe I should learn Haskell! Or I could try to untangle that horrible piece of code that’s been nagging at me.” Then, the first email of the day arrives in your inbox. It looks important and you figure you’d better respond to it so that it isn’t hanging over your head the rest of the day.
A few hours later it’s time for lunch and you realize you’ve spent the majority of the time fending off emails and trying to figure out where to get started. Half of your cherished free day is gone and you’ve got nothing substantial to show for it. Anything was possible, but now it seems like nothing is possible.
The Raw Materials of Innovation
Why is innovation so difficult? On the one hand, many of us have endless lists of ideas we’d love to spend time pursuing. We go about our day-to-day jobs yearning for a moment of freedom when we could forget about our responsibilities and try something totally new. And yet, when that moment presents itself to us, we feel unprepared or lost. The things which we thought would have motivated us seem to lose their appeal. Our interest fades and we hop from one idea to the next, never really getting anything done.
I recently attended a workshop on innovation and came away with some useful ideas for making innovation happen. One of the most valuable things I came away with is a more concrete definition of what innovation actually is.
So what is innovation? What makes something innovative? The common belief (or at least my prior belief) is that innovation is a novel idea - doing something that hasn’t been done before. So, if we want a group of people to be innovative, we should get together in a room and have a brainstorm of cool ideas. The more unique the idea or the approach, the more innovative.
The speakers at the workshop I attended provided a more useful definition. An innovation is the fulfilling of a customer’s need with a technology in a novel way. So, there are two essential components to innovation: customer needs and technologies. Innovative ideas result from the combination of needs and technologies in new ways.
At a previous job, I spent a couple of years working on a project which, in the end, had no real customer. We solved many technical challenges with this project and I’d even say that many of the ideas in the system we designed were quite novel. But, according to the definition above, we weren’t truly innovating because we weren’t solving a need. We were just building technology.
Customer needs and technologies are the raw materials for generating innovative ideas. This may help us better understand why it can be so difficult for us on that glorious free day to get beyond a blinking cursor in an empty text editor. Perhaps we lack the necessary building materials. Think about the times when you’ve had the best ideas, been the most engaged with your work, and been the most productive. For me, these times occur when there is a clear need and I’ve got (or can learn) the technical know-how to meet it.
So, the answer to moving forward is not to have a better brainstorm session, it’s to acquire more information. Are you the person who knows all sorts of programming languages and frameworks but can’t think of any good use for them? You need to spend some time finding a real customer problem that you can match up with some of this technology. On the other hand, maybe you’ve got a list of complaints from customers and don’t know where to begin. In this case, you may need a better view of the technology landscape.
Finding the Need
It probably goes without saying that finding real customer needs takes work. Most software companies have a product team whose mission is to understand and evaluate the importance of customer needs. In such cases, it is crucial for product folks and engineers to work together as a team. In general, product will supply the customer needs and engineers will supply technology. Together, they generate innovative solutions by evaluating which technologies are the best fit for the needs.
The degree to which a team is able to innovate is dependent upon how deep a team can go with the customer need. The deeper the team goes, the wider the solution space and the more technologies there are that can be applied to the problem - hence, more opportunity for innovative ideas. Any product manager will tell you that customers love to provide solutions and rarely begin by talking about the underlying need. By asking the right questions, the team can gain access to the deeper problem. The customer may say he needs a better horse, but what he really needs is a faster form of transportation. Or maybe what the customer really needs to spend less time traveling to and from work. The pool of available solutions increases dramatically based on how the problem is framed.
The speakers emphasized that the best opportunities for innovation come from needs that customers don’t realize they have. These are the needs that have likely never been addressed by any combination of technologies. According to the speakers, a customer will never realize there is a need unless they perceive some alternative. So just asking customers about their needs is not sufficient because you are likely to wind up with a list of problems for which solutions already exist.
One remedy for this is actually quite simple: go live life with the customer. The longer you sit with a customer as they use the product, the more opportunities you will have to see the hidden needs. If you find that the customer is using the product in an unexpected way, this could also indicate a hidden need.
Finding the Technology
So you’ve lived life with a customer, you’ve found a high impact need, now what? The speakers described an interesting approach to finding the right technology for a truly innovative solution. First, think about the core problem that must be solved and ask yourself “what other industry has faced a similar challenge?” Try to think far outside of your own industry. Then, go talk to folks in that industry and see what they’ve done to solve the problem. See if you can take their solution and apply it within your own problem domain.
The speakers gave several fun examples of this approach. When NASA began designing their first space suit, they had difficulty attaching the fabric and metal portions of the suit. Apparently, this is a pretty challenging thing to do, especially when someone’s life depends on the strength of the fabric/metal interface. NASA looked outside the space and military industries for a solution. They found an unlikely partner in the Playtex corporation, a popular producer of women’s undergarments. The problem of attaching fabric to metal is common in the design of bras and NASA was able to leverage Playtex’s experience in this domain to overcome their design challenges. At the time, NASA was embarrassed to admit that a portion of their space suit was developed by a bra company, so they contracted out to another company with the understanding that the real work would be sub-contracted to Playtex.
When looking to other industries for technologies, it’s wise to ask the people you talk to, “who has a similar problem, but even worse?” This can lead you people who have already solved the problem in really creative ways. The medical division of the 3M corporation was looking for a way to help surgeons prevent incisions from getting infected. They asked surgeons, “who might have an even harder time with infections than you?” This led them to investigate veterinarians, battlefield medics, and surgeons who operate on patients whose immune system has been compromised by chemotherapy. The key innovation for 3M’s product ultimately came from these discussions.
Similarly, the development of anti-lock brakes in cars came from an industry with a more extreme version of the problem. In this case, it was the airplane industry. Almost everything about this industry is more extreme. The stakes are higher, the speeds are faster, and icy runways cannot be salted because salt can damage aircraft. This made it a great candidate for solving a similar problem with automobiles.
When Should We Innovate?
How deep should a team dive into the customer’s needs? Indeed, opportunity for innovation increases, but so does the uncertainty for the project. With a large solution space, the team could spend ages finding and evaluating available technologies. And there is no guarantee that any of these technologies will pan out in the end. At the same time, there is the potential for immense gains. What if the team discovers a solution that eliminates an entire class of problems for the customer? Or, what if they find a solution that allows them to move ten times as fast? These could be game-changers for an entire industry.
One answer is that it depends on the business context. Maybe there is a short window of opportunity to make some key sales. Providing a feature within this timeframe will allow the company to get the sales while they are still available. The product manager may decide that these sales are more valuable than the potential for innovation and therefore focus the team on the immediate need. This may make sense given the context.
I think there are two dangers to avoid when approaching a project in this manner. First, it’s possible for a team to jump to a solution too quickly under pressure from the context. They may overlook a very simple solution to a deeper need and add unnecessary complexity to the product. This danger can be somewhat mitigated by at least timeboxing a brief exploration of the solution space.
The second danger occurs when the context forces the team to approach every problem at a surface level. History is replete with examples of organizations that failed because they got locked into addressing customer needs at a single level. I’m thinking specifically of Blockbuster and Kodak right now. These companies were once immensely successful, but they continued to solve problems the same way. They were ultimately destroyed by innovations which met customer needs at a deeper level.
Innovating Within an Organization
It’s clear that a company must innovate in order to survive long-term. In the initial startup phase of a company there isn’t much to lose and everything looks like an opportunity. Entrepreneurship and innovation are center stage. The problem is that companies become increasingly risk-averse as they grow. There is no immediate reason to change the way things are done when a company is enjoying a period of great success - if it ain’t broke, don’t fix it.
The speakers at the workshop talked about the value of a storm in these cases. A storm is some event that causes the leadership in a large organization to question the future. Examples include a competitor success or a new technological breakthrough. These events provide the motivation to accept more risk and make changes. In my view, a reliance on storms does not seem like a great way to run a business. Storms are unpredictable and may leave too little time for an organization to adjust. On the other hand, you might try to generate artificial storms, but this will eventually erode trust within the business.
Innovation is uncertain because it involves questions like, “is this problem even solvable?” An innovative solution could take many years to implement. The key to innovation within a larger organization is the recognition that uncertainty is not the same as risk. Uncertainty comes from our inability to predict the future. Risk is the impact of this uncertainty to the business. If you can find ways to mitigate risk, then you can still innovate even in the largest companies.
How do you mitigate risk? The same way you would do anything else with an agile mindset: start small and work in small increments. Don’t ask for a big budget or a large team right off the bat. Instead, find ways to show progress at each phase with the minimal resources at your disposal. As you demonstrate progress you may find that the organization is more willing to invest in your idea.
The 3M corporation is often cited as a company with a culture of innovation. Employees within 3M are allowed to work on whatever they want as long as they fulfill their day-to-day responsibilities reasonably well. It’s an environment that allows time for curiosity and exploration. The Post-It note was invented by a chemist at 3M who stumbled upon a unique adhesive while performing some experiments as part of a side-project. He knew his technology could be useful for something and he spent the next decade trying to figure out what that useful thing was.
Innovating at AppFolio
So how does all of this connect with work at AppFolio? Our second company value is: Great, innovative products are key to a great business.
I see several ways we strive to embody this value. First, product and UX spend an insane amount of time with our customers, talking to them, watching them, and deciphering their needs. They visit customer offices, they hang out with customers at meetups, they talk on the phone with customers all day, and they give customers demos of prototypes and new features.
As an organization, we are learning more and more how to drill down to the deep customer needs and make those the focus of our engineering efforts. We generally work without strict deadlines and this gives engineers a bit more freedom to ask questions and explore.
AppFolio provides engineers with a few regular opportunities to innovate. Every other Friday is Future Focused Friday. This is a day when engineers are free from their day-to-day responsibilities. They may use this day of work however they wish, without any accountability. Some engineers spend the day reading a book to deepen their understanding of a particular technology. Other engineers have projects that they are working on. For example, one engineer built a web app for sharing appreciations of other employees with the company. Still other engineers work on improving some part of our infrastructure or product. One engineer recently implemented an optimization in our continuous integration system which cut the runtime of our test suite in half.
Future Focused Friday is a zero-risk day. It frees engineers to try something crazy, like programing a drone to perform a property inspection or create a wireless submetering device. Because this day is already set aside, it costs the company nothing extra. In fact, these experiments may prove to be future streams of revenue for the business.
AppFolio hosts two hack days each year. Hack Day is similar to Future Focused Friday in that engineers can work on whatever they want for the day, but Hack Day tends to emphasize team projects and includes members of the company outside of engineering. A lot of cross-pollination between various parts of the company occurs on Hack Day. It’s also just plain fun. There are costumes, funny presentations, and beer. This gives the day a feeling of lighthearted playfulness and creativity.
We’ve recently introduced a new event to promote innovation called Shark Week. During this week, teams present innovative ideas they think will create value for our customers to a panel of judges. The judges select the project they think will have most value and the corresponding team has one month to implement it.
These are some basic structures and events that aim to promote innovation here at AppFolio. But just providing events doesn’t automatically make innovation happen. It takes an atmosphere of playfulness, curiosity, exploration, and, as I argue in this article, intense focus on customer needs and technology.
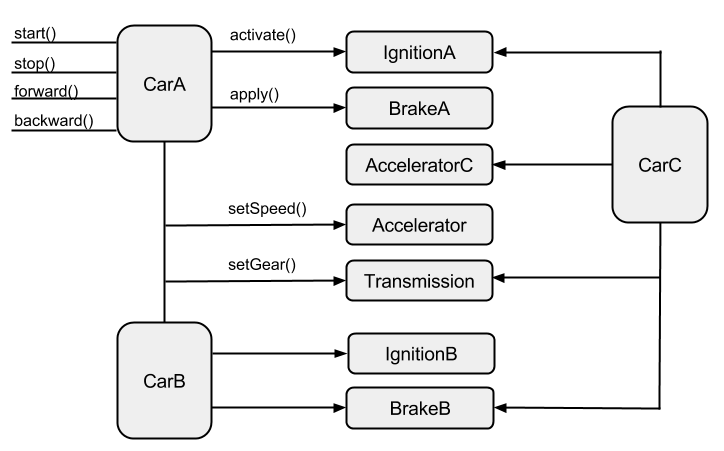
 I once had a mentor who liked to say, “If you can reduce it to a wiring problem, you’re half-way there.” It took me a while to really understand what this means and why it is useful advice for a software engineer. In this post, I’m going to do my best to explain it and provide you with some practical applications. I hope you find it helpful!
I once had a mentor who liked to say, “If you can reduce it to a wiring problem, you’re half-way there.” It took me a while to really understand what this means and why it is useful advice for a software engineer. In this post, I’m going to do my best to explain it and provide you with some practical applications. I hope you find it helpful!