by Ky-Cuong Huynh.
Overview
Interns at AppFolio are entrusted to contribute to real production work. After
2 weeks of training on AppFolio's processes and tools, I had the awesome
privilege of shipping code to production alongside my team every week since.
Along the way, I learned so much under the mentorship of fantastic engineers.
This led to the (technical) highlight of my summer: solving a race condition in
our Twilio usage and saving the company a significant amount of money every
year.
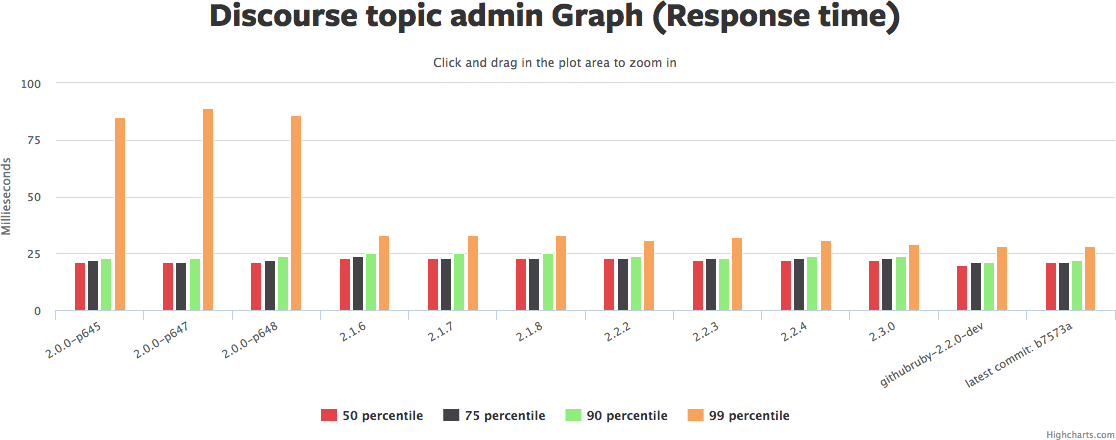
To understand how that race condition arose, here's a quick summary of our
multi-app architecture [0]: our production boxes run Passenger, a fast and
powerful app server. It achieves its speed by coordinating a pool of worker
processes to handle incoming requests. Then, for simplicity, we can think of
each of AppFolio's customers as having their own box that serves up the
AppFolio Property Manager (APM) they know and love.
When APM needs to communicate with Twilio's API, we have an internal app called
Messenger (also running on that same box). It accepts message-send requests
from other apps and acts as a middleman for Twilio, encapsulating all the logic
required. Multiple instances of Messenger may be running on a given box, one
per Passenger worker. As message-send requests arrive from APM, they may be
assigned to different workers. Now comes the race condition. If a customer has
sent too many messages in a 24-hour period, then Twilio recommends purchasing
another number to use. This prevents the first number from being marked as a
spam-sending one by carriers.
Unfortunately, more than one Passenger worker may believe it is necessary to buy
another phone number from Twilio, even if only one more number overall was
required. Thus, a customer may end up with more numbers than needed. That
introduces an unnecessary recurring expense for AppFolio, one that increases as
we have more customers.
Now, this was a known race condition. The team that built Messenger added a
lock around the provisioning code (our critical section/region). Alas,
Messenger instances can enter/exit the region one after the other. Even if only
one worker process executes the code at any point in time, we still end up with
multiple executions of the provisioning code.
Our solution: check if provisioning is actually necessary while inside of the
critical region. In other words, we added a check that asks, "Do I actually
need another phone number, or has enough sending capacity already been added?".
In the end, we spent far more time reasoning carefully than we did coding,
which is a common occurrence for complex real world problems.
Background
The bulk of my summer was spent working with my team on bulk texting
functionality. Our work empowered property managers to easily text whole units
or properties at once. Along the way, carrier limitations meant that we had
extended our messaging architecture to potentially map many phone numbers to
each customer. Towards the end, I learned of the interesting race condition
in question and began analyzing it. But first, some context.
Twilio's Quotas
At AppFolio, we use Twilio to send text messages.
Twilio recommends a rolling quota of 250/messages per 24-hour period. "Rolling" means that old messages no longer count against the quota once 24 hours have elapsed from the time they were sent. We can think of this a conveyor belt of messages, each of which returns to us for use after 24 hours. Note also that this is a soft limit, meaning that Twilio doesn't enforce this strictly. Rather, if we send more than 250 messages/24 hour period for a single phone number, that number risks being marked as a spam number by carriers. If a number is marked as a spam number, then its messages may be silently filtered out from ever reaching their recipients.
There's one more wrinkle. When a conversation is seen as "conversational" by carriers, there is a higher threshold for blacklisting numbers as spam senders. These also vary by carrier, but Twilio recommends 1,000 messgages per (rolling) 24-hour period when a communication is more 2-way. To be safe, our internal limits model this conversational threshold as a +1 to the quota for every message received.
Sending Messages Using Messenger
Messenger is essentially our internal middleman for Twilio. Every app that needs to send text messages can do so by sending a request to Messenger, which will handle the back-and-forth with Twilio. Messenger itself presents a set of JSON APIs that are message-oriented. It's designed to take in requests for sending a single message. It has no concept of groups/batches of messages
(which is something we considered adding to speed up sending bulk texts).
Here's an overview diagram:

The Race Condition
To make things more concrete, we'll walk through the code flow for sending a bulk text.
In Property, our TenantBulkSmsService is invoked to create a background job for sending requests to Messenger. Messenger receives the request from Property and sends the message using TwilioInterface::Sender.send_message:
class << self
def send_message(body:, to_phone_number:, ignore_sending_limit: false)
# Check customer quota and message length
raise DailyLimitExceeded, # ...
raise BodyTooLong, # ...
# RACE CONDITION entrance: we potentially provision as part of the
# Twilio configuration
config = verify_and_load_twilio_config
# Send message with the proper parameters
prepared_message = TwilioInterface::PreparedMessage.new(body: body, to_phone_number: to_phone_number)
response = config.twilio_subaccount_client.send_message(
# From:, To:, Body:, etc.
# ...
)
# If here, successful message send
TwilioInterface::Sender::SuccessfulResponse.new(twilio_response: response)
# Else, Twilio error handling
rescue Twilio::REST::ServerError
# ...
That verify_and_load_twilio_config method leads to the retrieve method here:
module TwilioInterface
class PhoneNumberManager
class << self
def retrieve
# RACE CONDITION: more than one Messenger instance
# may find this condition to be true and proceed to provisioning logic
if need_provision?
TwilioInterface::PhoneNumberProvisioner.provision!
end
end
# Other class methods
# ...
That need_provision check is later down this same file:
def need_provision?
if Experiments.on?(:texting_quota)
(TwilioInterface::DailyLimitChecker.current_amount_under_limit < 1) && !reach_max_capacity?
else
!provisioned?
end
end
The race condition occurs here: more than one Passenger worker process (running Messenger) may
enter this method and find TwilioInterface::DailyLimitChecker.current_amount_under_limit to be < 1. Then, they would all proceed to TwilioInterface::PhoneNumberProvisioner.provision!:
def provision!(purchase_filter = {})
create_new_number(purchase_filter)
end
So we go to create_new_number:
def create_new_number(purchase_filter = {})
# RACE CONDITION consequence: multiple Passenger workers
# may enter this critical region one at a time and each
# purchase an (soon unnecessary) number
lock = Lock.first
lock.with_lock do
unless PhoneNumberManager.reach_max_capacity?
# Provision new phone number
# ...
end
end
rescue Twilio::REST::RequestError => e
raise TwilioNumberNotPurchasable, e
end
This is where the phone number purchase actually occurs. Notice that the
purchasing logic is protected by a lock. This is a leftover from when a
previous team originally implemented this code and noticed the race condition.
They solved it for the single phone-number case, but now we had to generalize
to multiple phone numbers. At this point, my mentors and I understood the
race condition and were ready to solve it.
Aside: A Database-based Lock
You may have wondered why we're not using the Mutex class built into Ruby's standard library. In fact, if we dig into that Lock implementation, it's just using a single row in a table on the database. So why are we using the database to implement a lock?
Here's why: our issue is not coordinating multiple threads on a single machine (or guarding against interrupts with a single thread), but rather multiple processes that are potentially across multiple machines. This is because customers may have more than one physical box running Passenger (though this race condition can still occur in the multi-process, single-box case). Any mutex we create would only exist in the memory of one of those boxes.
What stops this from becoming a full-blown distributed systems problem is the fact that everything in a box shares a single database. We can leverage that shared database to coordinate/synchronize access to this piece of code. This is possible because MySQL uses its own locks as part of achieving its ACID properties. Then, the biggest users of those locks are transactions.
To make use of all this, the Lock#with_lock [2] method simply wraps the passed-in block code in a transaction. To test this unusual lock, we opened two Rails consoles and had one try to enter the critical region after another had already done so. We found that the lock did indeed prevent access, at least until it was released. Note, however, that ActiveRecord appears to have a default timeout for how long to wait to acquire a lock.
The Fix
The fix for this race condition is surprisingly simple. At its core, we face the issue that Messenger processes are checking against how many phone numbers a customer may have, rather than the capacity they may have already gained. So, we simply add this check to the critical section:
def create_new_number(purchase_filter = {})
lock = Lock.first
lock.with_lock do
if TwilioInterface::PhoneNumberManager.need_provision?
# Provision
# ...
And recall that that check looked like this:
def need_provision?
if Experiments.on?(:texting_quota)
(TwilioInterface::DailyLimitChecker.current_amount_under_limit < 1) && !reach_max_capacity?
else
!provisioned?
end
end
Now, a natural question is "Why wouldn't we simply add the database-based lock around the first need_provision? check?"
Answer: because that method is called for every single message to be sent, whereas actually provisioning more numbers only happens on occasion. Whenever locks are used, we're defining a critical region of code that can only be accessed by one process at a time. This makes a tradeoff of safety vs. speed. Putting a lock around the first need_provision? overly widens our critical region and reduces message throughput.
Verifying the Fix
To check the fix, we'll want to modify some of our method calls to simplify testing. To start, we'll stub the provisioning logic lock to let us know
what occurred:
def create_new_number(purchase_filter = {})
lock = Lock.first
lock.with_lock do
if TwilioInterface::PhoneNumberManager.need_provision?
PhoneNumber.create!(
twilio_subaccount_id: 7,
sid: "#{Random.rand(100)}",
number: "+#{Random.rand(100)}",
friendly_name: "+#{Random.rand(100)}"
)
puts "I provisioned a new number!"
else
puts "I did not provision a new number"
end
end
Next, we modified the database and calls so that the first number is exhausted. Note that test messages must be dated for today because of the 24-hour rolling quota!
And when we run:
TwilioInterface::PhoneNumberProvisioner::provision!
Then, the first console says, "I provisioned a new number!", but the second console to execute this gives, "I did not provision a new number". Race condition resolved! We were also able to devise a test case to guard against regressions. That test now runs as part of every continuous integration (CI)
build.
If anyone has any questions, I can be reached on Twitter or via email at kycuonghuynh@ucla.edu.
Appreciations
Thank you to Yunlei and Magne for collaborating with me on this.
You were both amazing mentors and truly made my summer. I've grown so
much under your careful guidance and I can't wait to keep learning and building.
Thank you to Flavio for regression testing this fix. AppFolio cares highly
about the level of quality delivered to its customers and you serve as a
strong advocate for them.
Thank you to Jingyu and Chris (authors of the original Messenger code) for encouraging me to pursue a fix and then helping me understand Messenger.
Finally, thank you to Andrew for letting me write about this, as well as editing this post and recruiting me to AppFolio.
[0] A review of the concurrency material from OSTEP, a free operating systems textbook, can also be helpful.
[1] Using a code texted to a device as part of login is really using 2SV,
second-step verification, since the code is still a piece of knowledge.
This belongs to the the same class of factors as passwords ("something you know"). A Yubikey or biometrics requirement would constitute a true second factor ("something you have" and "something you are", respectively).
[2] It is Ruby convention to refer to instance methods in documentation via ClassName#instance_method.