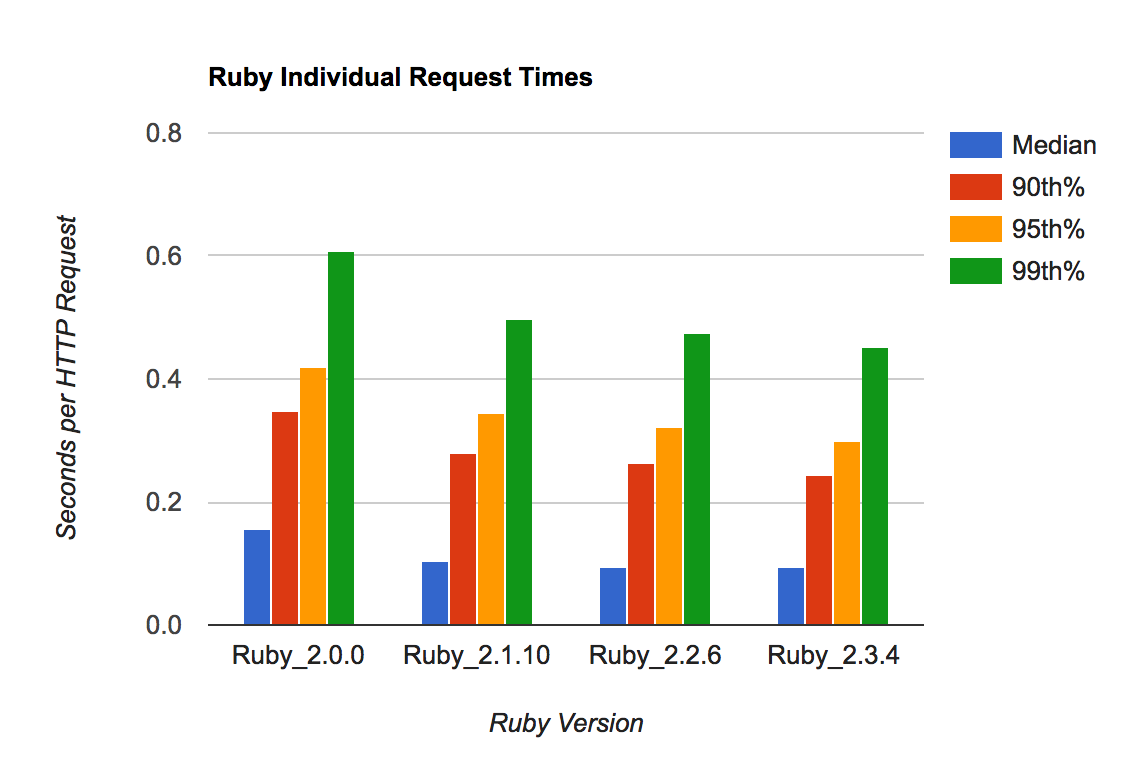
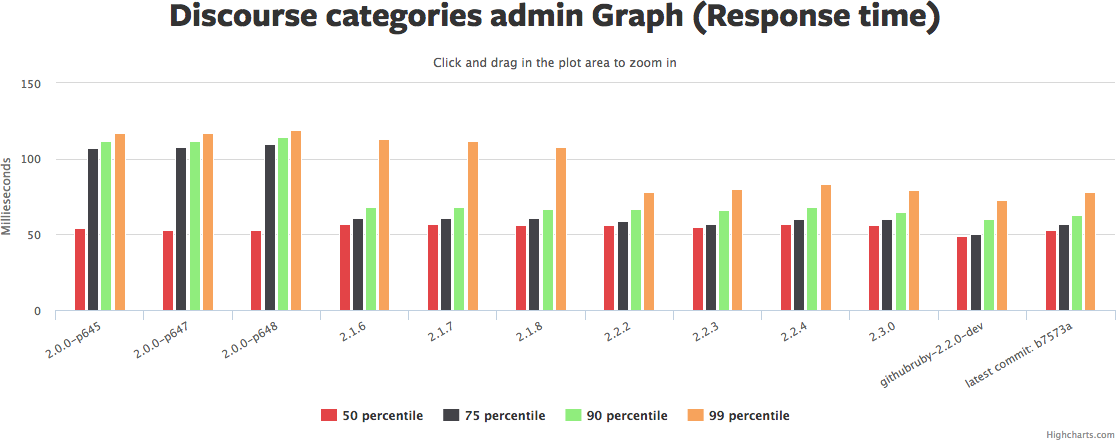
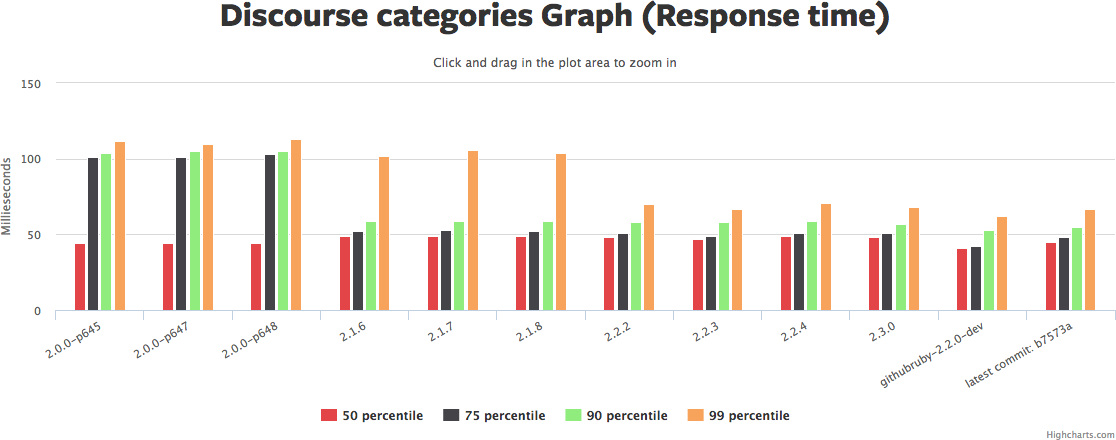
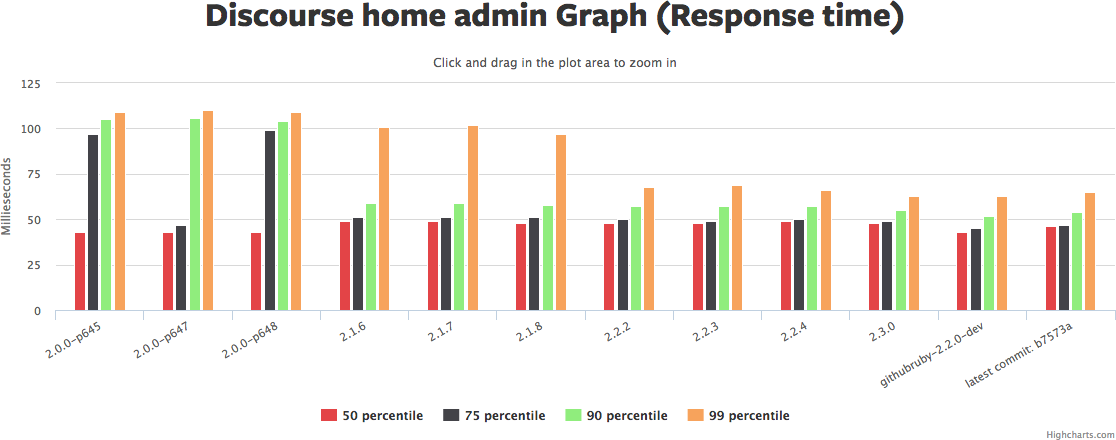
Ruby, RubyGems and Bundler can be a bit of an intertwined mess -- it can be hard to tell what magic incantation will tell you what went wrong and how to fix it.
The secret is that they're three separate layers. Ruby was originally designed without RubyGems. RubyGems is a separate layer on top with a few seams where it was designed to be detached. Bundler was created for Rails 3.0, and was built on top of a perfectly good RubyGems to add more functionality.
In other words, it makes sense to learn them separately even if you'll only use them together. Otherwise, how can you tell what's wrong with what library?
We won't discuss version managers like rvm, rbenv or chruby here. Rest assured that they're another whole layer with their own power and subtleties. They do interact with gems, not only the Ruby executable.
I found this talk by Andre Arko after writing this - he mentions a whole setup.rb step in between Require and RubyGems that you can ignore completely. It has a lot of great additional detail and history.
Ruby
Ruby, at its lowest level, doesn't really have "libraries" built in. It has the ability to "load" or "require" a file, and it has $LOAD_PATH, an array of paths to check when you ask for a filename.
"Load" just does what it says: read the file and execute the Ruby inside. It's almost the same as if you'd just written "eval File.read('filename')", except that it checks the paths in the $LOAD_PATH, in order, to figure out where to find your filename. Well, and it also executes inside a top-level Ruby object called "main" rather than exactly where you called "eval". Still, it's a pretty straightforward command.
"Require" is just slightly more complicated. It keeps a hash of what files have already been required. If you ask for a new one, it will load it. If you ask for a file you've already required, it will do nothing. "Require" also tries hard to not re-require different paths if they point to the same file -- think of symbolic links between directories, for instance, or relative pathnames versus absolute. Require tries to chase down the "real" canonical location of the file so it can avoid requiring the same file twice except in pretty extreme circumstances.
Ruby starts with a few default entries in the $LOAD_PATH. You may want to pop into irb and type "$LOAD_PATH" to see what they are for you. An old version of Ruby like 1.8.6 had even fewer since RubyGems wasn't loaded until you manually required it. In recent versions, you can see that RubyGems is installed by default - you're likely to see some gems automatically in the $LOAD_PATH.
You'll also notice that the current directory (".") isn't in the $LOAD_PATH. Long ago it used to be. These days it isn't. That's why you can't just "require 'myfile'" and have it magically find myfile.rb from the current directory. I mean, unless you stick "." into the $LOAD_PATH array, but that's not a common thing to do.
RubyGems
RubyGems is a library on top of Ruby. You can upgrade it separately from your Ruby language version. RubyGems also has some command-line commands and strong opinions that old versions of Ruby didn't originally have.
The "gem" command will show you a lot about how RubyGems is currently set up. Specifically, try typing "gem env" and see all the good stuff:
RubyGems Environment:
- RUBYGEMS VERSION: 2.5.1
- RUBY VERSION: 2.3.1 (2016-04-26 patchlevel 112) [x86_64-darwin15]
- INSTALLATION DIRECTORY: /Users/noah.gibbs/.rvm/gems/ruby-2.3.1
- USER INSTALLATION DIRECTORY: /Users/noah.gibbs/.gem/ruby/2.3.0
- RUBY EXECUTABLE: /Users/noah.gibbs/.rvm/rubies/ruby-2.3.1/bin/ruby
- EXECUTABLE DIRECTORY: /Users/noah.gibbs/.rvm/gems/ruby-2.3.1/bin
- SPEC CACHE DIRECTORY: /Users/noah.gibbs/.gem/specs
- SYSTEM CONFIGURATION DIRECTORY: /Users/noah.gibbs/.rvm/rubies/ruby-2.3.1/etc
- RUBYGEMS PLATFORMS:
- ruby
- x86_64-darwin-15
- GEM PATHS:
- /Users/noah.gibbs/.rvm/gems/ruby-2.3.1
- /Users/noah.gibbs/.rvm/gems/ruby-2.3.1@global
- GEM CONFIGURATION:
- :update_sources => true
- :verbose => true
- :backtrace => false
- :bulk_threshold => 1000
- REMOTE SOURCES:
- https://rubygems.org/
- SHELL PATH:
- /Users/noah.gibbs/.rvm/gems/ruby-2.3.1/bin
- /Users/noah.gibbs/.rvm/gems/ruby-2.3.1@global/bin
- /Users/noah.gibbs/.rvm/rubies/ruby-2.3.1/bin
- /usr/local/bin
- /usr/bin
- /bin
- /usr/sbin
- /sbin
- /Users/noah.gibbs/.rvm/bin
There are a bunch of environment variables that affect where and how Ruby finds gems. "Gem env" shows you where they're all currently pointed. Useful!
That list of "GEM PATHS" tell you what RubyGems puts into the $LOAD_PATH to let Ruby find your gems. The "INSTALLATION DIRECTORY" is where "gem install" will put stuff.
RubyGems does some interesting things, but it's mostly an extension of $LOAD_PATH. It doesn't do as much fancy stuff as you might think. As a result, it doesn't have any ability to find things that aren't locally installed - you can't use a gem from Git using RubyGems for instance, because how and when would you update it? RubyGems has a path it installs to, a few paths it looks through, and the ability to turn a directory of files into an archive (a "gem file", but not at all like "Gemfile") and back.
The last one is interesting. You can "gem build" a gemfile, if you have a .gemspec file in the right format. It's just a YAML manifest of metadata and an archive of files, all compressed into a single ".gem" archive. But you can push it to remote storage, such as RubyGems.org or a local gem server (see GemInABox for an example.)
That's also how "gem install" works - it downloads a .gem archive, then unpacks it to a local directory under the "INSTALLATION DIRECTORY". The reason for things like "spec cache" above is that to download .gem archives, RubyGems wants to know who has what versions of what gems, and what platforms and Ruby versions they're compatible with. The spec files have that information but not the whole archive of files. That's so that they're smaller and quicker to download.
One more subtlety: gems are allowed to build native extensions. That is, they can link to system libraries and build new files when you install them. So this is a *bit* more complicated than just unpacking an archive of Ruby files into place. It can also involve fairly convoluted install steps. But they're basically a run-on-install shell script to build files. This is also why every Ruby version you have installed saves its own copy of every gem. If a gem builds an extension, that's compiled against your local Ruby libraries, which are different for every version of Ruby. So that copy of Nokogiri actually has different files in the Ruby 2.3.1 copy than in the Ruby 2.4.0 copy or the Ruby 1.9.3 copy. That's what happens when you build them each with different libraries, it turns out.
RubyGems is more complicated than plain old "load" and "require." But nothing I've described is terribly magical, you know?
Bundler
Bundler is a much more powerful, complex and subtle tool than RubyGems. It has more weird behaviors that you have to understand, and it enables a lot more magic.
It solves a lot of long-standing RubyGems problems, and replaces them with a new crop of Bundler-specific problems. No tool can just "do what you want" without you having to describe what you want. Bundler is no exception.
You can tell you're using Bundler when you're messing with the Gemfile and Gemfile.lock, or when you use the "bundle" command. You can also start Bundler from your Ruby files. That's why Rails commands run with Bundler active, but don't start with the "bundle" command.
The first thing Bundler does is to make undeclared gems "invisible." If it's not in your Gemfile, you can't require it. That's really powerful because it means somebody else can tell what gems you were actually *using*. It also makes undeclared gem *versions* invisible. So if you have five versions of JSON installed (don't laugh, it happens), this will make sure you get the right one and only the right one. This trick requires "bundle exec" (see below.)
It also has "bundle install". If you have a list of all the gems you can use, it makes sense to just let you install them. That's probably the most wonderful magic in Bundler. If you remember the old system of gem declarations in Rails' environment.rb, you understand just how incredible Bundler is. If you don't remember it... That's probably for the best.
Similarly, it has a Gemfile.lock with the specific version of all your gems. So even if you give a range of legal versions of MultiJSON, the Gemfile.lock will list the specific one you're currently using. That way, everybody else will also get the same version when they "bundle install" using your Gemfile.lock. For complex but good reasons, you should check in an application's Gemfile.lock so that everybody gets the same versions you do, but you should *not* check in a library's Gemfile.lock because you *can't* make everybody use your same dependencies. Oy.
Bundler also figures out which Gem versions are compatible with which other versions. When Bundler creates Gemfile.lock, it makes sure that the whole set of different gem versions works together, and that they get activated in the right order with all the right versions. Getting all your gem versions loaded in the right order used to be a very ugly process. Bundler fixes it.
Bundler can also use somewhat-dynamic gems. Specifically, you can declare a "git" URL in your Gemfile and Bundler will check it out locally and make sure it gets into your $LOAD_PATH so that "require" works. The Gemfile can also take gems with a ":path" option to point to un-installed local gems, such as in a checked-out repo. Both of these things require Bundler to be active inside your Ruby process -- just setting $LOAD_PATH isn't enough, the Bundler library has to be active. Be sure to run with "bundle exec" or this won't work.
Bundler still does a lot of this with $LOAD_PATH magic. The rest is done by loading its library into your Ruby process, changing how "require" works. It gets loaded via "Bundler.setup" in Ruby, or something like Rails or "bundle exec" that calls it. There may also be a sacrifice of goats involved, so check your version number carefully.
Because Bundler needs to be running inside your Ruby process, you'll need to activate it. The easiest way to do this manually is to type "bundle exec" in front of your process name. That will find the right Gemfile, set an environment variable so that sub-processes running Bundler will use the same one, and generally make sure everything gets properly loaded. Just be careful - if you run a sub-process that also runs Ruby, it can be hard to make sure it's using the same Bundler in the same way. When in doubt, run "bundle exec" in front of the command line if there's any chance that it could run something in Ruby.
Bundler also has a facility for "vendoring" gems -- that is, copying specific versions to a local directory and using them there, not from system directories. That can be valuable, but the way Bundler does it is kind of magical and kind of brain-bending. It's better than the old RubyGems method of copying the files to a local directory and replacing $LOAD_PATH. But it's still pretty weird.
If you're having trouble figuring out what's going on in Bundler, the answer is usually "bundle exec". For instance, "bundle exec gem env" will show you where Gems get installed or loaded with Bundler active, which can be a huge revelation. "Oh, *that's* why I'm not seeing it." Similarly, running things like "bundle exec gem list --local" shows you what Bundler can and can't see. That's very powerful.
There are rumors that Bundler will wind up built into RubyGems. If that happens, it will eliminate some of the headaches with subprocesses and manually running "bundle exec". That would be awesome. In the mean time you're going to need to know more about this than you'd like. I feel your pain, I promise.