

Besides GC, Has Ruby 2.3 Helped Rails Performance?
/You may have read recently about how Rails performance has changed with recent Ruby versions. In that post, I concluded that newer Ruby is using a bit more memory, and has improved performance for the slowest requests by a lot. But that benchmark is pretty dependent on garbage collection (aka GC,) at least for the worst requests. You can read the original post for all the numbers of how things changed, and it's pretty clear that GC figures in significantly.
What if we measure Rails performance without garbage collection? What does it look like then?
(Just want more pretty graphs? Scroll down.)
How We Measure
Garbage collection and multiple threads interact a lot. It's really hard to tease performance apart when GC may be happening in the background. And it's hard to turn off GC when you're running lots of threads and they're generating lots of garbage. So for this post, we're measuring single-threaded straight-line performance. We're still measuring 1500 requests, just sequentially instead of in parallel.
Incidentally, don't directly compare request times or thread times between this post and the last one. I've started using an EC2 m4.2xlarge instance instead of a t2.2xlarge. Similar, but not the same. It allows me to use dedicated placement -- I'm not sharing my VM with other people's random VMs for the benchmark, which is a really, really good thing. However, the CPU is slightly slower. Also, this entire post uses single-process, single-threaded, single-load-tester performance numbers, which are completely different than the highly concurrent numbers in the previous post. This post measures things like "how long does it take one Puma worker to process 1500 requests while idling in between?" The previous post was measuring "how long does it take 30 load testers to each get 50 requests processed by 10 Puma processes using 60 Puma threads?" So: different results.
I put together a modified version of Puma, the app server used by my benchmark, that would allow me to manually trigger GC and report GC stats. And I wrote up a modified branch of the benchmark code to GC immediately before the 1500 requests. I had mostly debugged a solution to GC in between every request to not count GC time before I realized... with a major GC before 1500 consecutive requests on a single thread, on an EC2 m4.2xlarge, it never GCs anyway. At least, not after the first manually-triggered GC. So I verified that it didn't GC, but I didn't need to force it to GC in between requests, nor turn off GC manually.
Results
As with the previous benchmark, I ran the benchmark 11 times against Ruby versions 2.0.0, 2.1.10, 2.2.6 and 2.3.4. As with the previous version, there were no failed requests out of those 44 runs.
First we'll look at the performance, then we'll check side-by-side with the previous results. Remember that raw times are different, so you're looking at the curve of the graph. Also note the vertical scale of the second graph - it shows significant changes, but not nearly as huge as they look.
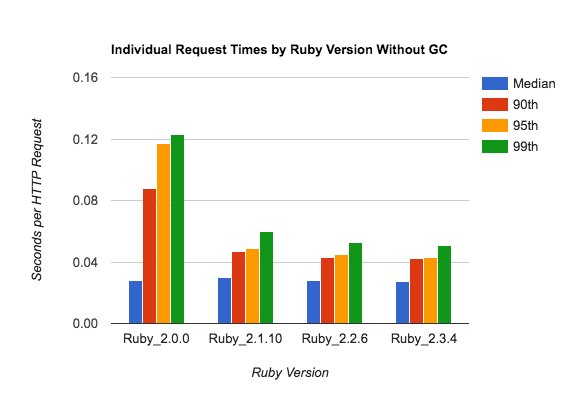
The first graph shows various percentile request times for individual requests, so the total is 16500 samples per Ruby version:
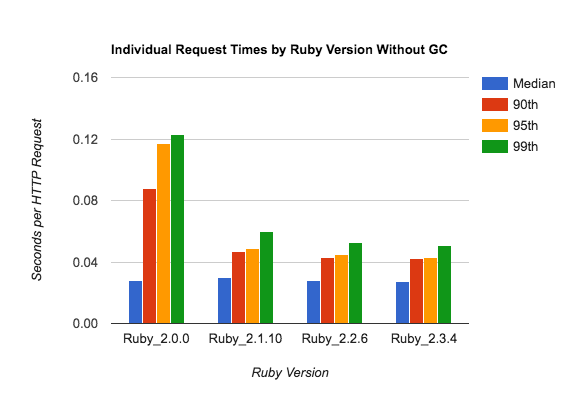
Without garbage collection, the 50th-percentile (blue) and 99th-percentile (green) request are within about a factor of two - not bad.
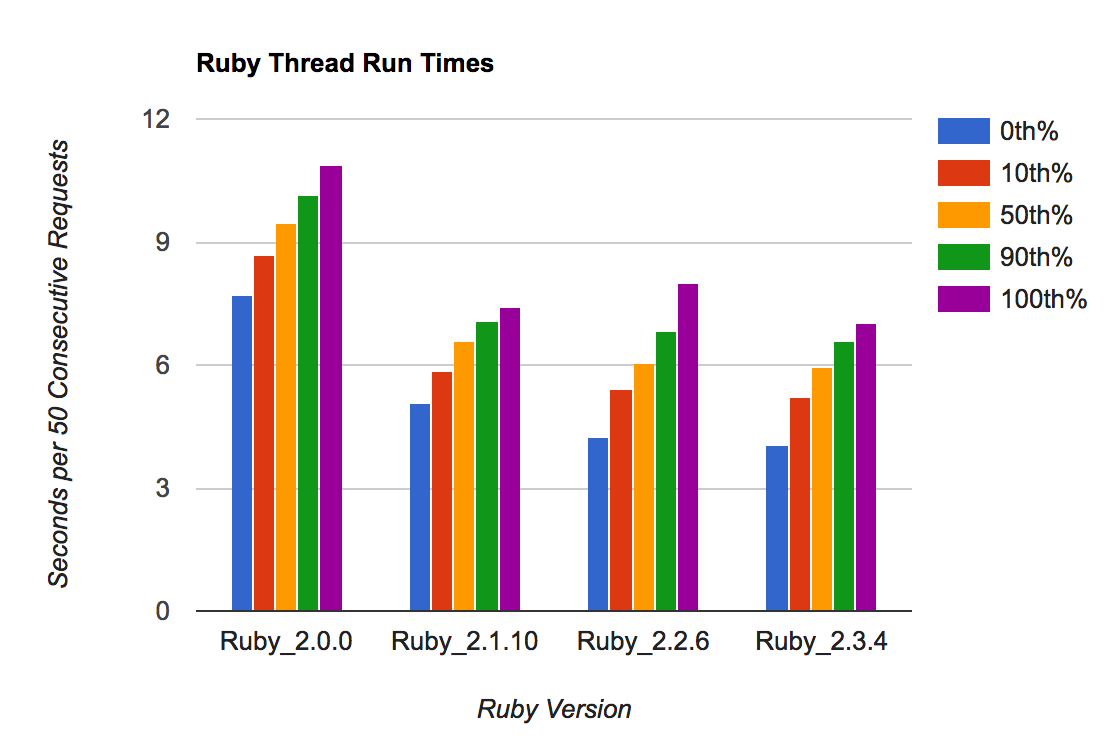
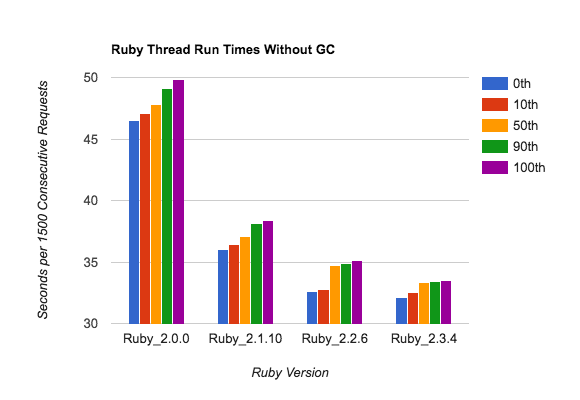
The second graph shows the aggregate runtimes for all 1500 consecutive requests, so you're seeing 11 samples per Ruby version (remember, single-threaded):

This is a very small sample size, but adding together 1500 requests/sample gives you some stability. There's not a lot of run-to-run variability. Note the vertical scale - these change by around 30%, not 5x.
Let's see these side-by-side with the previous post's "with GC" results.
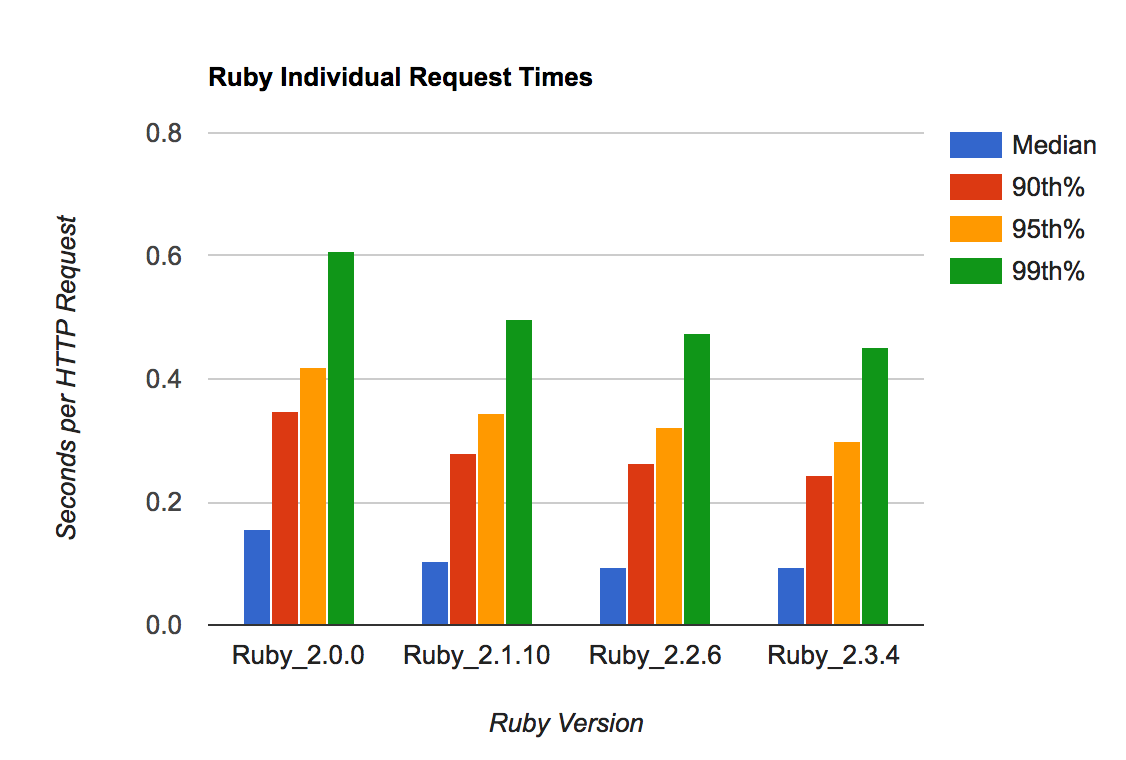
(Again, remember the bottom right graph starts at 30 on the vertical scale.)
The better and worse requests are much more similar in the GC-less (right-side) graphs. And GC doesn't affect just the 99th percentile - the 90th and 95th percentile are also farther from the median when GC is active. That makes sense, because GC runs in the background and can slow down many requests, not just requests where it first activates.
I also think just the medians (blue) tell an interesting story. Specifically: with no GC, the median request hasn't changed at all between Ruby 2.0 and 2.3, but slower requests improved by better than 50% (2x speed). Median-and-faster requests didn't change. All the non-GC Ruby 2.3 improvement for the median thread (not request) is coming from the slowest 30% of its 1500 requests. Email me if you'd like my JSON test data to run the same test. Or you can just reproduce the results for yourself.
So: every thread run has improved about 30% without GC, pretty much entirely from fixing its slowest requests. The median thread run with GC also improved about 30% (see left-hand graphs.) Every thread run has also improved about 30% with GC.
So: the garbage collector sped up by at least 30% between Ruby 2.0 and 2.3 (more, arguably) and sped up pretty evenly across requests. Non-GC speed optimizations were about the same, 30%, but concentrated far more on slow requests, with fast requests staying about the same.

Again, the numbers on the left and right are different setups. They're very apples-to-oranges. You're just looking for "oh, the median request improves over 30% with GC, and not at all without it."
Receipts
If you're curious about my methodology, you can see my code on GitHub. It uses a modified Discourse 1.5.0 (same version as in the previous blog post, for the same reasons explained there.) The only change from normal Discourse is that it uses that specific modified Puma by Git SHA from my GitHub fork of Puma.
I'm still working on getting my benchmark working with the Discourse 1.8.0 betas, which support Ruby 2.4.0.