

Ruby Register Transfer Language - But How Fast Is It on Rails?
/I keep saying that one of the first Ruby performance questions people ask is, “will it speed up Rails?” I wrote a big benchmark to answer that question - short version: I run a highly-concurrent Discourse server to max out a large, dedicated EC2 instance and see how fast I can run many HTTP requests through it, with requests meant to simulate very simple user access patterns.
Recently, the excellent Vladimir Makarov wrote about trying to alter CRuby to use register transfer instead of a stack machine for passing values around in its VM. The article is very good (and very technical.) But he points out that using registers isn’t guaranteed to be a speedup by itself (though it can be) and it mostly enables other optimizations. Large Rails apps are often hard to optimize. So then, what kind of speed do we see with RTL for Rails Ruby Bench, the large concurrent Discourse benchmark?
JIT
First, an aside: Vlad is the original author of MJIT, the JIT implementation in Ruby 2.6. In fact, his RTL work was originally done at the same time as MJIT, and Takashi Kokubun separated the two so that MJIT could be separately integrated into CRuby.
In a moment, I’m going to say that I did not speed-test the RTL branch with JIT. That’s a fairly major oversight, but I couldn’t get it to run stably enough. JIT tends to live or die on longer-term performance, not short-lived processes, and the RTL branch, with JIT enabled, crashes frequently on Rails Ruby Bench. It simply isn’t stable enough to test yet.
Quick Results
Since Vlad’s branch of Ruby is based (approximately) on CRuby 2.6.0, it seems fair to test it against 2.6.0. I used a recent commit of Vlad’s branch. You may recall that 2.6.0 JIT doesn’t speed up Rails, or Rails Ruby Bench, yet either. So the 2.6-with-JIT numbers below are significantly slower than JITless 2.6. That’s the same as when I last timed it.
Each graph line below is based on 30 runs, with each using 100,000 HTTP requests plus 100 warmup requests. The very flat, low-variance lines you see below are for that reason - and also that newer Ruby has very even, regular response times, and I use a dedicated EC2 instance running a test that avoids counting network latency.
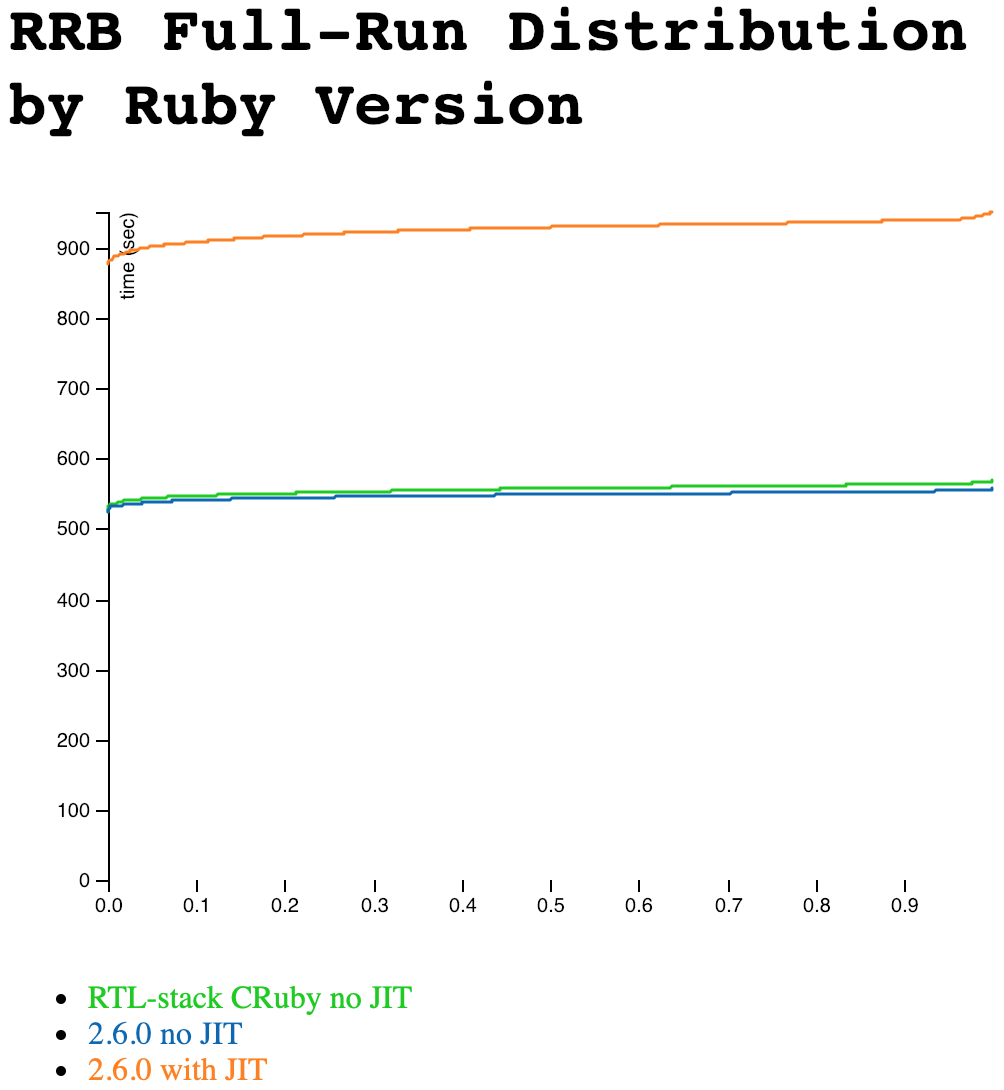
Hard to tell those top two apart, isn’t it?
You’ll notice that it’s very hard to tell the RTL and stack-based (normal) versions apart, though JIT is slower. We can zoom in a little and chop the Y axis, but it’s still awfully close. But if you look carefully… it looks like the RTL version is very slightly slower. I haven’t shown it on this graph, but the variance is right on the border of statistical significance. So RTL may, possibly, be just slightly slower. But there’s at least a fair chance (say one in three?) that they’re exactly the same and it’s a measurement artifact, even with this very large number of samples.
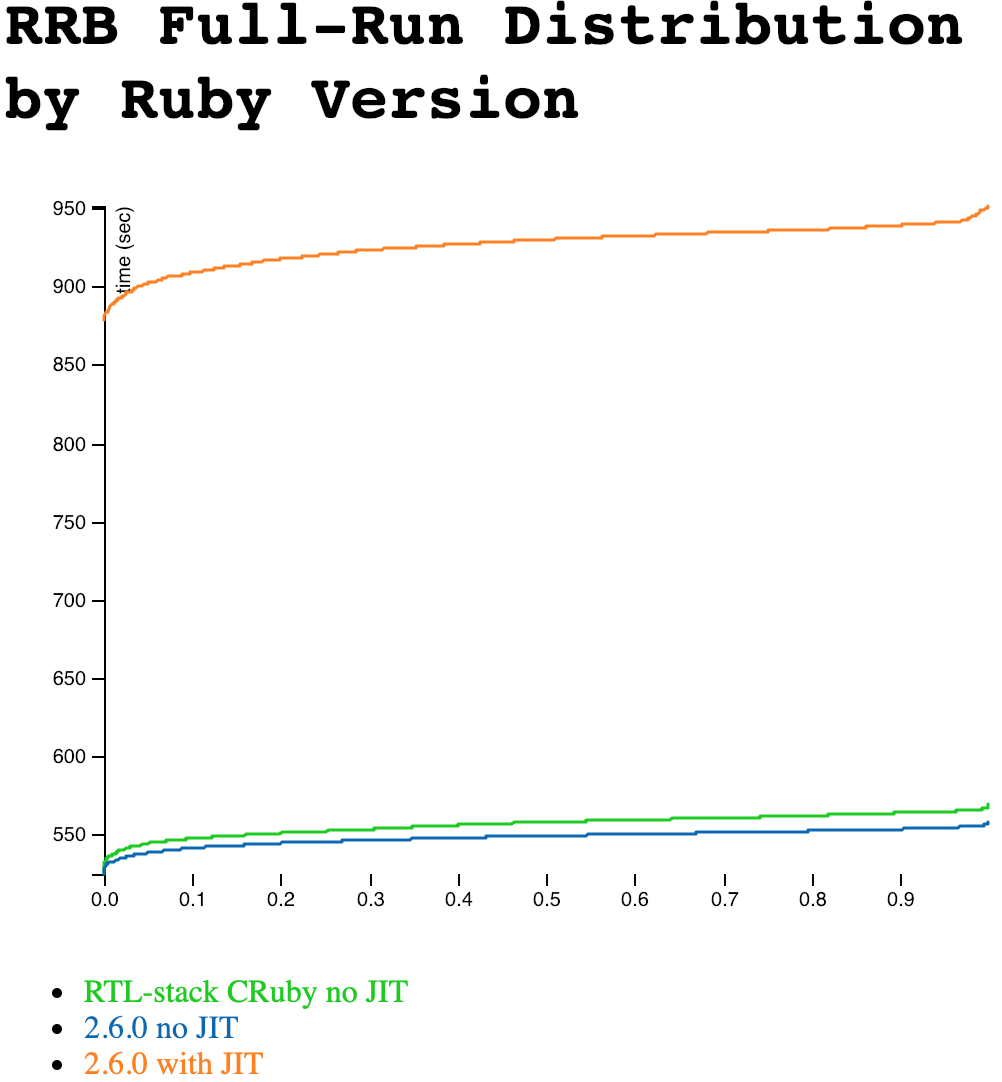
Conclusions
I often feel like Rails Ruby Bench is unfair to newer efforts in Ruby - optimizing “most of” Ruby’s operations is frequently not enough for good RRB results. And its dependencies are extensive. This is a case where a promising young optimization is doing well, but — in my opinion — isn’t ready to roll out on your production servers yet. I suspect Vlad would agree, but it’s nice to put numbers to it. However, it’s also nice to see that his RTL code is mature enough to run non-JITted with enough stability for very long runs of Rails Ruby Bench. That’s a difficult stability test, and it held up very well. There were no crashes without supplying the JIT parameter on the command line.