

A Simpler Rails Benchmark, Puma and Concurrency
/I’ve been working on a simpler Rails benchmark for Ruby, which I’m calling RSB, for awhile here. I’m very happy with how it’s shaping up. Based on Rails Ruby Bench, I’m guessing it’ll take quite some time before I feel like it’s done, but I’m finding some interesting things with it. And isn’t that what’s important?
Here’s an interesting thing: not every Rails app is equal when it comes to concurrency and threading - not every Rails app wants the same number of threads per process. And it’s not a tiny, subtle difference. It can be quite dramatic.
(Just want to see the graphs? I love graphs. You can scroll down and skip all the explanation. I’m cool with that.)
New Hotness, Old and Busted
You’ll get some real blog posts on RSB soon, but for this week I’m just benchmarking more "Hello, World” routes and measuring Rails overhead. You can think of it as me measuring the “Rails performance tax” - how much it costs you just to use Ruby on Rails for each request your app handles. We know it’s not free, so it’s good to measure how fast it is - and how fast that’s changing as we approach Ruby 3x3 and (we hope) 3x the performance of Ruby 2.0.
For background here, Nate Berkopec, the current reigning expert on speeding up your Rails app, starts with a recommendation of 5 threads/process for most Rails apps.
You may remember that with Rails Ruby Bench, based on the large, complicated Discourse forum software, a large EC2 instance should be run with a lot of processes and threads for maximum throughput (latency is a different question.) There’s a diminishing returns thing happening, but overall RRB benefits from about 10 processes with 6 threads per process (for a total of 60 threads.) Does that seem like a lot to you? It seems like a lot to me.
I’m gonna show you some graphs in a minute, but it turns out that RSB (the new simpler benchmark) actually loses speed if you add very many threads. It very clearly does not benefit from 6 threads per process, and it’s not clear that even 3 is a good idea. With one process and four threads, it is not quite as fast as one process with only one thread.
A Quick Digression on Ruby Threads
So here’s the interesting thing about Ruby threads: CRuby, aka “Matz’s Ruby,” aka MRI has a Global Interpreter Lock, often called the GIL. You’ll see the same idea referred to as a Global VM Lock or GVL in other languages - it’s the same thing.
This means that two different threads in the same process cannot be executing Ruby code at the same time. You have to hold the lock to execute Ruby code, and only one thread in a process can hold the lock at a time.
So then, why would you bother with threads?
The answer is about when your thread does not hold the lock.
Your thread does not hold the lock when it’s waiting for a result from the database. It does not hold the lock when sleeping, waiting on another process finishing, waiting on network I/O, garbage collecting in a background thread, running code in a native (C) extension, waiting for Redis or otherwise not executing Ruby code.
There’s a lot of that in a typical Rails app. The slow part of a well-written Rails app is waiting for network requests, waiting for the database, waiting for C-based libraries like libXML or JSON native extensions, waiting for the user…
Which means threads are useful to a well-written Rails app, even with the GIL, up to around 5 threads per process or so. Potentially it can be even more than 5 — for RRB, 6 is what looked best when I first measured.
But Then, Why…?
Here’s the thing about RSB. It’s a “hello, world” app. It doesn’t use Redis. It doesn’t even use the database. And so it’s doing only a little bit where CRuby threads help, because of the GIL. Only a little HTTP parsing. No JSON or XML parsing.
Puma does a little more that can be parallelized, which is why threads help at all, even a little.
So: Discourse is near the high end of how many threads help your Rails app at around 6. But RSB is just about the lowest possible (2 is often too many.)
Okay. Is that enough conceptual and theoretical? I feel like that’s plenty of conceptual and theoretical. Let’s see some graphs!
Collecting Data
I’ve teased about finding some things out. So what did I do? First off, I picked some settings for RSB and ran them. And in the best traditions of data collection, I discovered a few useful things and a few useless things. Here’s the brief, cryptic version… Followed by some explanation:
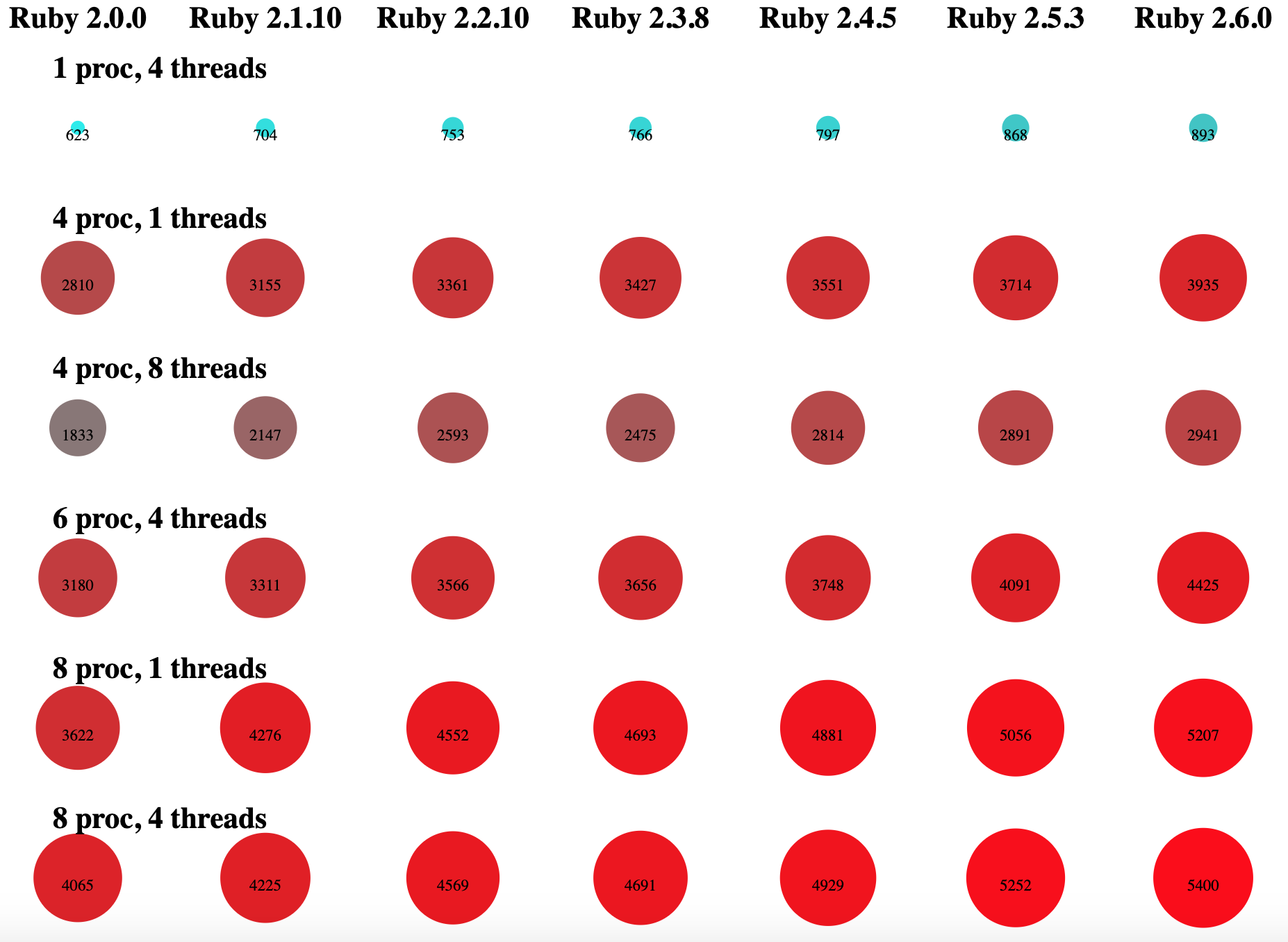
Clear as mud, right?
The dots in the left column are for Ruby 2.0.0, then Ruby 2.1.10, 2.2.10, etc., until the rightmost dots are all Ruby 2.6. See how the dots get bigger and redder? That’s to indicate higher throughput — the throughputs are in HTTP requests/second, and are also in text on each dot. Each vertical column of dots uses the same Ruby version.
Each horizontal row of dots uses the same concurrency settings - the same number of processes and threads. You can see a key to how many of each over on the left.
What can we conclude?
First, the dots get bigger from left to right in each row, so Ruby versions gets faster. The “Rails performance tax” gets significantly lower with higher Ruby versions, because they’re faster. That’s good.
Also: newer Ruby versions get faster at about the same rate for each concurrency setting. To say more plainly: different Ruby versions don’t help much more or less with more processes or threads. No matter how many processes or threads, Ruby 2.6.0 is in the general neighborhood of 30% faster than Ruby 2.0.0 - it isn’t 10% faster with one thread and 70% faster with lots of threads, for instance.
(That’s good, because we can measure concurrency experiments for Ruby 2.6 and they’ll mostly be true for 2.0.0 as well. Which saves me many hours on some of my benchmark runs, so that’s nice.)
Now let’s look at some weirder results from that graph. I thought the dots would be clearer for the broad overview. But for the close-in, let’s go back to nice, simple bar graphs.
Weirder Results
Let’s check out the top two rows as bars. Here they are:

The Ruby versions go 2.0 to 2.6, left to right.
What’s weird about that? Well, for starters, 1 process with four threads is less than one-fourth of the speed of 4 processes with one thread. If you’re running single-process, that kinda sounds like “don’t bother with threads.”
(If you already read the long-winded explanation above you know it’s not that simple, and it’s because RSB threads really poorly in an environment with a Global Interpreter Lock. If you didn’t — it’s a benchmark! Feel free to quote this article out of context anywhere you like, as long as you link back here :-) )
Here’s that same idea with another pair of rows:

Kinda looks like “just save your threads and stay home,” doesn’t it?
It tells the same story even more clearly, I think. But wait! Let’s look at 8 processes.

The Triumphant hero shot: a case where 4 threads are… well, maybe marginally better than 1. Barely.
Also, this was the final graph. You can CMD-W any time from here on out.
That’s a case where 4 threads per process give about a 10% improvement over just one. That’s only noteworthy because… well, because with fewer processes they did more harm than good. I think what you’re seeing here is that with 8 processes, you’re finally seeing enough not-in-Ruby I/O and context switching that there’s something for the extra threads to do. So in this case, it’s really all about the Puma configuration.
I am not saying that more threads never help. Remember, they did with Rails Ruby Bench! And in fact, I’m looking forward to finding out what these numbers look like when I benchmark a Rails route with some real calculation in it (probably even worse) or a few quick database accesses (probably much better.)
You might reasonably ask, “why is Ruby 2.6 only 30% faster than Ruby 2.0?” I’m still working on that question. But I suspect part of the answer is that Puma, which is effectively a lot of what I’m speed-testing, uses a lot of C code, and a lot of heavily-tuned code that may not benefit as much from various Ruby optimizations… It’s also possible that I’m doing something wrong in measuring. I plan to continue working on it.
How Do I Measure?
First off, this is new benchmark code. And I’m definitely still shaking out bugs and adding features, no question. I’m just sharing interesting results while I do it.
But! The short version is that I set up a nice environment for testing with a script - it runs the trials in a randomized order, which helps to reduce some kinds of sampling error from transient noise. I use a load-tester called wrk, which is recommended by the Phusion folks and generally quite good - I examined a number of load testers, and it’s been by far my favorite.
I’m running on an m4.2xlarge dedicated EC2 instance, and generally using my same techniques from Rails Ruby Bench where they make sense — a very similar data format, for instance, to reuse most of my data processing code, and careful tagging of environment variables and benchmark settings so I don’t get them confused. I’m also recording error rates and variance (which effectively includes standard deviation) for all my measurements - that’s often a way to find out that I’ve made a mistake in setting up my experiments.
It’s too early to say “no mistakes,” always. But I can set up the code to catch mistakes I know I can make.
I’d love for you to look over the benchmark code and the data and visualizations I’m using.
Conclusions
It’s tempting to draw broad conclusions from narrow data - though do keep in mind that this is pretty new benchmark code, and there could be flat-out mistakes lurking here.
However, here’s a pretty safe conclusion:
Just because “most Rails apps” benefit from around five threads/process doesn’t mean your Rails or Ruby app will. If you’re mostly just calculating in Ruby, you may want significantly fewer. If you’re doing a lot of matching up database and network results, you may benefit from significantly more.
And you can look forward to a lot more work on this benchmark in days to come. I don’t always publicize my screwed up dubious-quality results much… But as time marches forward, RSB will keep teaching me new things and I’ll share them. Rails Ruby Bench certainly has!