

Revolutionizing PropTech with LLMs
/Our flagship product, AppFolio Property Manager (APM), is a vertical software solution designed to help at every step when running a property management business. As APM has advanced in complexity over the years, with many new features and functionalities, an opportunity arose to simplify user actions and drive efficiency. Enter AppFolio Realm-X: the first generative AI conversational interface in the PropTech industry to control APM - powered by transformative Large Language Models (LLMs).
AppFolio Realm-X
Unlike traditional web-based systems of screens, Realm-X acts as a human-like autonomous assistant to the property manager. Realm-X empowers users to engage with our product through natural conversation, eliminating the need for time-consuming research in help articles and flattening the learning curve for new users. Realm-X can be asked general product questions, retrieve data from a database, streamline multi-step tasks, and automate repetitive workflows in natural language without an instruction manual. With Realm-X, property managers can focus on increasing the scale of their businesses while increasing critical metrics, such as occupancy rates, tenant retention, NOI, and stakeholder satisfaction.
Why LLMs?
Distinguished by their unmatched capabilities, LLMs set themselves apart from traditional Machine Learning (ML) approaches, which predominantly rely on pattern matching and exhibit limited potential for generalization. The distinctive features of LLMs include:
Reasoning capabilities: Unlike traditional approaches, LLMs can reason, enabling them to comprehend intricate contexts and relationships.
Adaptability to new tasks: LLMs can tackle tasks without requiring task-specific training. This flexibility allows for a more streamlined and adaptable approach to handling new and diverse requirements. For example, if we change the definition of an API, we can immediately adapt the model to it. We don’t need to go through a slow and costly cycle of annotation and retraining.
Simplifying model management: LLMs eliminate the need to manage numerous task-specific models. This consolidation simplifies the development process, making it easier to maintain and scale.
LLM Pre-training and Fine-tuning
The first step in creating an LLM is the pre-training stage. Here, the model is exposed to diverse and enormous datasets encompassing a significant fraction of the public internet, commonly using a task such as next-word prediction. This allows it to draw on a wealth of background knowledge about language, the world, entities, and their relationships - making it generally capable of navigating complex tasks.
After pre-training, fine-tuning is applied to customize a language model to excel at a specific task or domain. Over the years, we have used this technique extensively (with smaller language models such as RoBERTa) to classify messages within Lisa or Smart Maintenance or extract information from documents using generative AI models like T5. Fine-tuning LLMs makes them practical and also unlocks surprising new emergent abilities - meaning they can accomplish tasks they were never explicitly engineered for.
Instruction following: During pre-training, a model is conditioned to continue to the current prompt. Instead, we often want it to follow instructions so that we can steer the model via prompting.
Conversational: Fine-tuning conversational data from sources such as Reddit imbues the ability to refer back to previous parts of the conversation and distinguish instructions from the text it generated itself and other inputs. This allows users to engage in a back-and-forth conversation to iteratively refine instructions or ask clarifying questions while reducing the vulnerability to prompt injections.
Safety: Most of the fine-tuning process concerns preventing harmful outputs. A model adapted in this way will tend to decline harmful requests.
Adaptability to new tasks: Traditional ML techniques require adaptation to task-specific datasets. On the other hand, fine-tuned LLMs can draw on context and general background knowledge to adapt to new tasks through prompting, known as zero shot. Additionally, one can improve accuracy by including examples, known as few shot, or other helpful context.
Reasoning from context: LLMs are especially suited for reasoning based on information provided together with the instructions. We can inject portions of documents or API specifications and ask the model to use this information to fulfill a query.
Tool usage: Like humans, LLMs exhibit weaknesses in complex arithmetic, precise code execution, or accessing information beyond their training data. However, like a human using a calculator, code interpreter, or search engine, we can instruct an LLM about the tools at its disposal. Tools can dramatically enhance their capabilities and usefulness since many external systems, including proprietary search engines and APIs, can be formulated as tools.
With a generic model with generic capabilities, the problem remains: how do we adapt it so that a user of our software can use it to run their business?
Breaking Down a User Prompt
Once a user enters a prompt in the chat interface, Realm-X uses an agent paradigm to break it into manageable subtasks handled by more specialized components. To break down the prompt into more manageable subtasks, the agent is provided with:
A description of the domain and the task it has to complete, along with general guidelines
Conversation history
Dynamically retrieved examples of how to execute a given task and,
A list of tools
A description of the task and the conversation history defines the agent's environment. It allows users to refine or follow up on previous prompts without repeating themselves. Because we provide the agent with a set of known scenarios, the agent can retrieve the ones most relevant to the current situation – improving reliability without polluting the prompt with irrelevant information.
The agent must call relevant tools, interpret their output, and decide the next step until the user query is fulfilled. Tools encapsulate specific subtasks like data retrieval, action execution, or even other agents. They are vital because they allow us to focus on a subset of the domain without overloading the primary prompt. Additionally, they allow us to parallelize the development process, separate concerns, and isolate different parts of the system. We allow the agent to select tools and generate their input - and tools can even be dynamically composed – such that the output of a tool can be the input for the next.
Generally, a tool returns:
Structured data to be rendered in the UI
Machine-readable data to be used for automation tasks
A string that summarizes the result to be interpreted by the main agent (and added to the conversation history)
Realm-X in Action
Let’s look at an example of tools in action through two requests Realm-X receives via a single, natural language prompt. A more in-depth analysis of tools will be explored in later posts. The prompt asks Realm-X to 1. Gather a list of residents at their property, The Palms, and 2. Invite the residents via text to a community barbecue on Saturday at 11 AM.
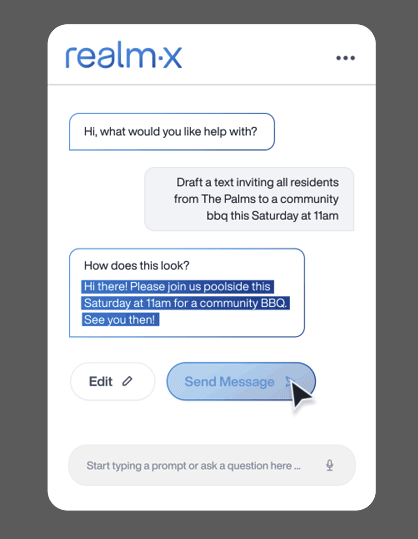
Realm-X returns a draft bulk message
A user can manually update the message or refine it with follow-up prompts
Recipients are pre-populated
While not displayed above, placeholders can be added to personalize each message
This allows users to quickly create bulk communication, where the reports and content can be customized to many situations relevant to running their business. We aim to expand the capabilities to cover all actions that can be performed inside APM, from sending renewal offers to scheduling inspections. The next step is combining business intelligence and task execution with automation. Our users can put parts of their business on auto-pilot, allowing them to focus their time and energy on building relationships and improving the resident experience rather than on repetitive busy work.
The Road Ahead
Integration of LLMs represents a shift in how we develop software. For one, we don’t have to build custom forms and reports for every use case but can dynamically compose the building blocks. With some creativity, users can even compose workflows we haven’t considered ourselves. We also learned that LLMs are an impartial check on our data and API models – if a model can’t reason its way through, a non-expert human (developer) will also have a hard time. All future APIs must be modeled with an LLM as a consumer in mind, requiring good parameter names, descriptions, and structures representing the entities in our system.
This post only scratches what we can do with this exciting technology. We will follow up with more details surrounding the engineering challenges we encountered and provide a more detailed view into the architectural choices, user experience, testing and evaluation, accuracy, and safety.
Stay tuned!
Authors and Contributors: Chrisftried Focke, Tony Froccaro