

Benchmark Results: Threads, Processes and Fibers
/You may recall me writing an I/O-heavy test for threads, processes and fibers to benchmark their performance. I then ran it a few times on my Mac laptop, wrote the numbers down and called it a day.
While that can be useful, it’s now how we usually do benchmarking around here. So let’s do something with a touch more rigor, shall we?
Also some pretty graphs. I like graphs.
Methodology
If you’re the type to care about methodology (I am!) then this is a great time to review the previous blog post and/or the code to the tests.
I’ve written a simple master/worker pattern in (separately) threads, fibers and processes. In each case, the master writes to the worker, which reads, writes a response, and waits for the next write. This is very simple, but heavy on I/O and coordination.
For this post, I’ll be timing the results for not just threads vs fibers vs processes, but also for Rubies 2.0 through 2.6 - specifically, CRuby versions 2.0.0-p0, 2.1.10, 2.2.10, 2.3.8, 2.4.5, 2.5.3 and 2.6.2.
I’ll mention “workers” for all these tests. For thread-based testing, a “worker” is a thread. Same for processes and fibers - one worker is one process or one fiber.
First Off, Which is Faster?
It’s hard to definitively say which of the three methods of concurrency is faster in general. In fact, it’s nearly a meaningless question since they do significantly different things and are often combined with each other.

Now, with sanity out of the way, let’s pretend we can just answer that with a benchmark. You know you want to.
The result for Ruby 2.6 is to the right.
It looks as if processes are always faster assuming you don’t use too many of them.
And that’s true, sort of. Specifically, it’s true until you start to hit limits on memory or number of processes, and then it’s false. That’s probably why you’re seeing that rapid rise in processing time for 1,000 processes. These are extremely simple processes - if you’re doing more real work you wouldn’t use 1,000 workers because you’d run out of memory long before that.
However, for a simple task like this, fibers beat threads because they’re lighter-weight, using less memory or CPU. And processes beat both, because they get around Ruby’s use of the GIL, and it’s such a tiny task that we don’t hit memory constraints until we use close to 1,000 processes - a far larger number of workers than is useful or productive.
In fact, you would normally use multiple of these. You can and should use multiple threads or fibers per process with multiple processes in CRuby to avoid GIL issues. Yeah, fine, real-world issues. Let’s ignore them and have more fun with graphs. Graphs are awesome.
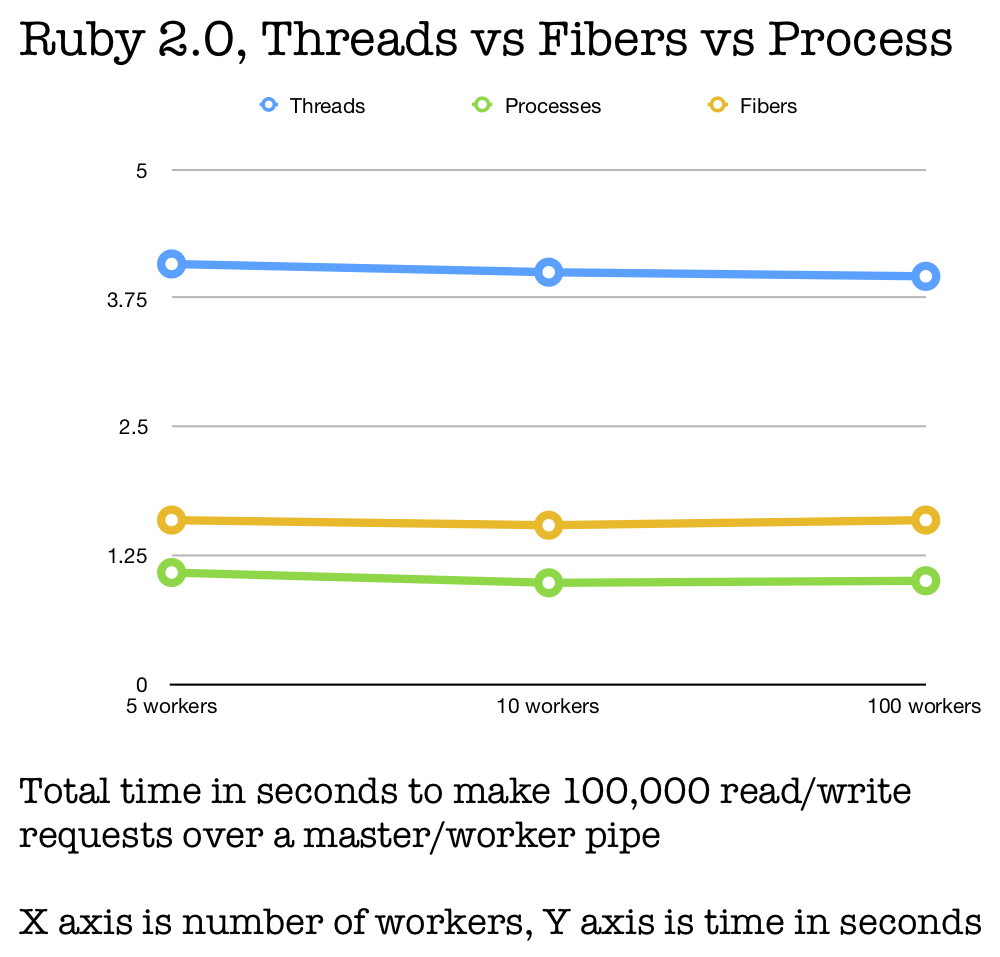
You might (and should) reasonably ask, "but is this an artifact of Ruby 2.6?” To the right are the results for Ruby 2.0, for reference. They do not include 1,000 workers because Ruby 2.0 segfaults when you try that.
Processes Across the Years
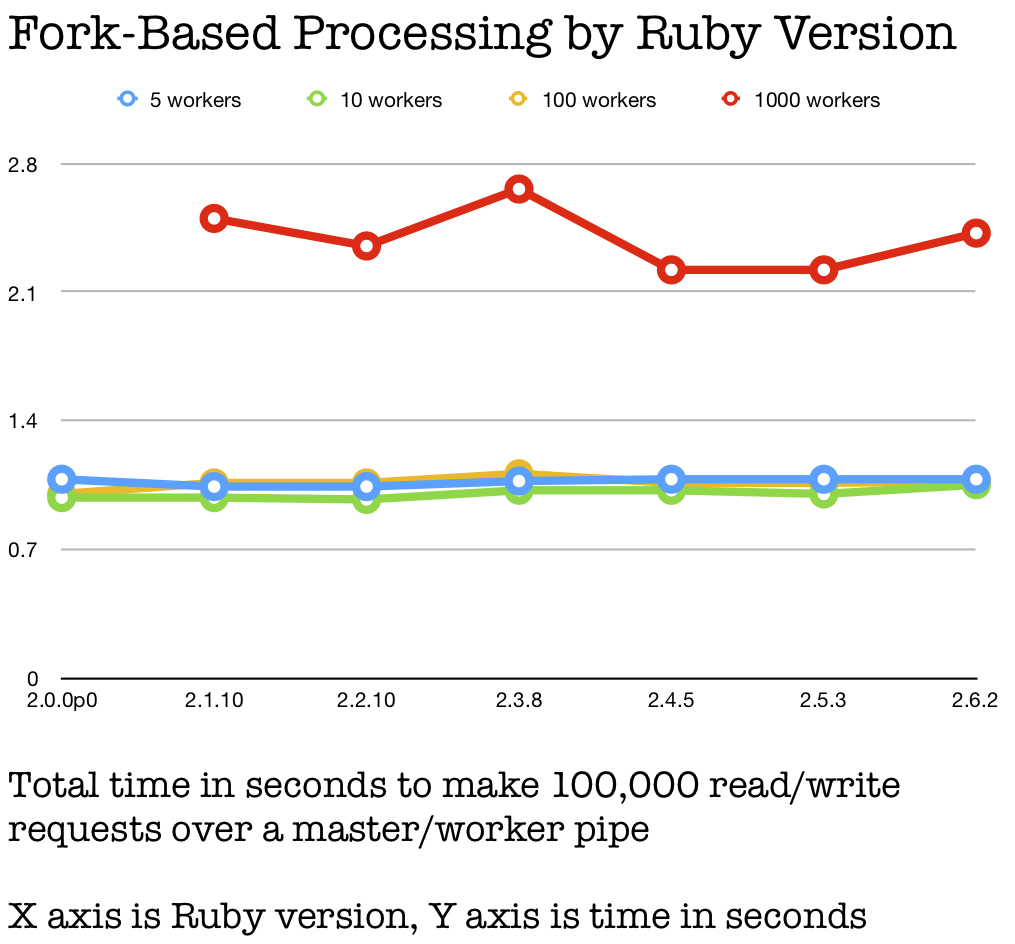
How has our Ruby multiprocess performance changed since Ruby 2.0? That’s the baseline for Ruby 3x3, so it can be our baseline here, too.
If you look to the right, the short answer is that if you use a reasonable number of workers the performance is excellent and very stable. If you use a completely over-the-top number of workers, the performance isn’t amazing. I wouldn’t really call that a bug.
Incidentally, that isn’t just noisy data. While I only ran each test 10 times, the variance is very low on the results. Ruby 2.3.8 and 2.6.2 just seem to be (reliably) extra-bad with far too many processes. Of course, that’s a bad idea on any Ruby, not just the extra-bad versions.
In general, though, Ruby processes are living up to their reputation here - CRuby has used processes for concurrency first and foremost. Their performance is excellent and so is their stability.
Though you’ll notice that the “1,000 processes” line doesn’t go all the way back to Ruby 2.0.0-p0, as mentioned above. That’s because it gets a segmentation fault and crashes the Ruby interpreter. That’s a theme - fibers and threads also crash Ruby 2.0.0-p0 when you try to use far too many of them. But Ruby 2.1 has fixed the problem. I hope that doesn’t mean you need to upgrade, since Ruby 2.1 is almost six years old now…
Threads Across the Years

That was processes. What about threads?
They’re pretty good too. And unlike processes, thread performance has improved pretty substantially between Ruby 2.0 and 2.6. That’s nearly twice as fast for an all-coordination, all-I/O task like this one!
1,000 threads is still far too many for this task, but CRuby handles it gracefully with only a slight performance degradation. It’s a minor tuning error, not a horrible misuse of resources like 1,000 processes would be.
What you’re seeing there, with 5-10 threads being optimal for an I/O-heavy workload, is pretty typical of CRuby. It’s hard to get great performance with a lot of threads because the GIL keeps more than one from running Ruby at once. Normally with 1,000 threads, CRuby’s performance will fall off a cliff - it simply won’t speed up beyond something like 6 threads. But this task is nearly all I/O, and so the GIL does fairly minimal harm here.
Fibers Across the Years
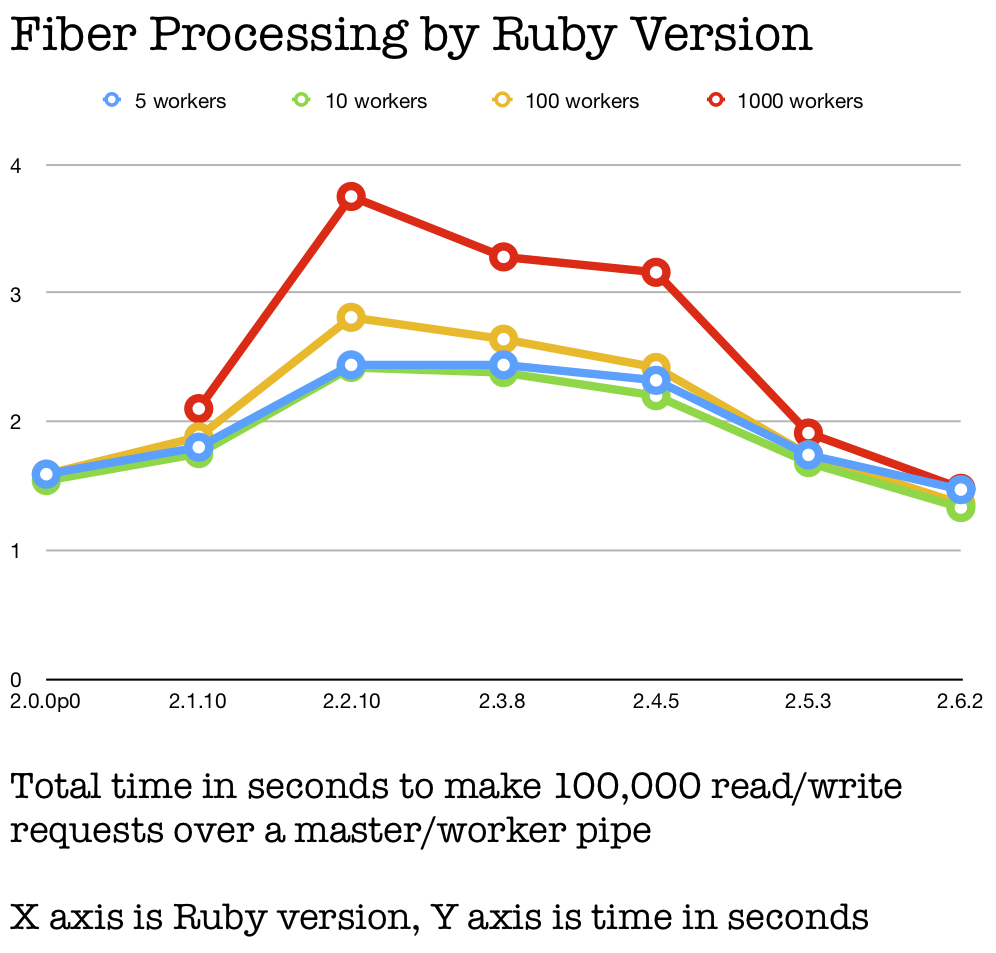
Fibers are the really interesting case here. We know they’ve received some rewriting love in recent Ruby versions, and I’ve seen Fiber.yield times significantly improved from very old to very new CRuby. Their graph is to the right. And it is indeed interesting.
First, 1,000 fibers are clearly too many for this task, as with threads and processes. In fact, threads seem to handle the excess workers better, at least until 2.6.
Also, fibers seem to get worse for performance after 2.0 until 2.6 precipitously fixes them. Perhaps that’s Samuel Williams’ work?
It’s also fair to point out that I only test fibers (or threads or processes, for that matter) with a pure-Ruby reactor. All of this assumes that a simple IO.select is adequate, when you can get better performance using something like nio4r to use more interesting system calls, and to do more of the work in optimized C.
Addendum: Ruby 2.7
I did a bit of extra benchmarking of (not yet released) Ruby 2.7, with the September 6th head-of-master commit. The short version is that threads and processes are exactly the same speed as 2.6 (makes sense), while fibers have gained a bit more than 6% speed from 2.6.
So there’s more speed coming for fibers!
Conclusions
Clearly, the conclusion is to only use processes in CRuby, ever, and to max out at 10 processes. Thank you for coming to my TED talk.
No, not really.
Some things you’re seeing here:
Fibers got faster in Ruby 2.6 specifically. If you use them, consider upgrading to Ruby 2.6+.
Be careful tuning your number of threads and processes. You’ve seen me say that before, and it’s still true.
Threads, oddly, have gained a bit of performance in recent CRuby versions. That’s unexpected and welcome.
Thank you and good night.